Delving into Kubernetes
I have recently been learning and using Kubernetes in my homelab as a means to manage a lot of self-hosted apps. Overall I’ve been pretty happy with it and it has helped simplify my setup.
The first question to answer is why to use a system such as this in the first place. In the last 10 years or so there has been quite a shift in the way that people deploy and run their applications and resources. In the beginning there was bare metal where you would have one physical machine with one OS that hosted multiple applications. Then virtualisation came along and allowed people to segregate those applications so that they had their own OS stack for each, isolating the resources which caused less conflicts and allowed for easier management. More recently we’ve got containerisation platforms which make far better use of the available resources by sharing low level components with the host OS. Tools such as Docker have given an easy means of packaging and deploying containers which also helped contribute to their popularity.
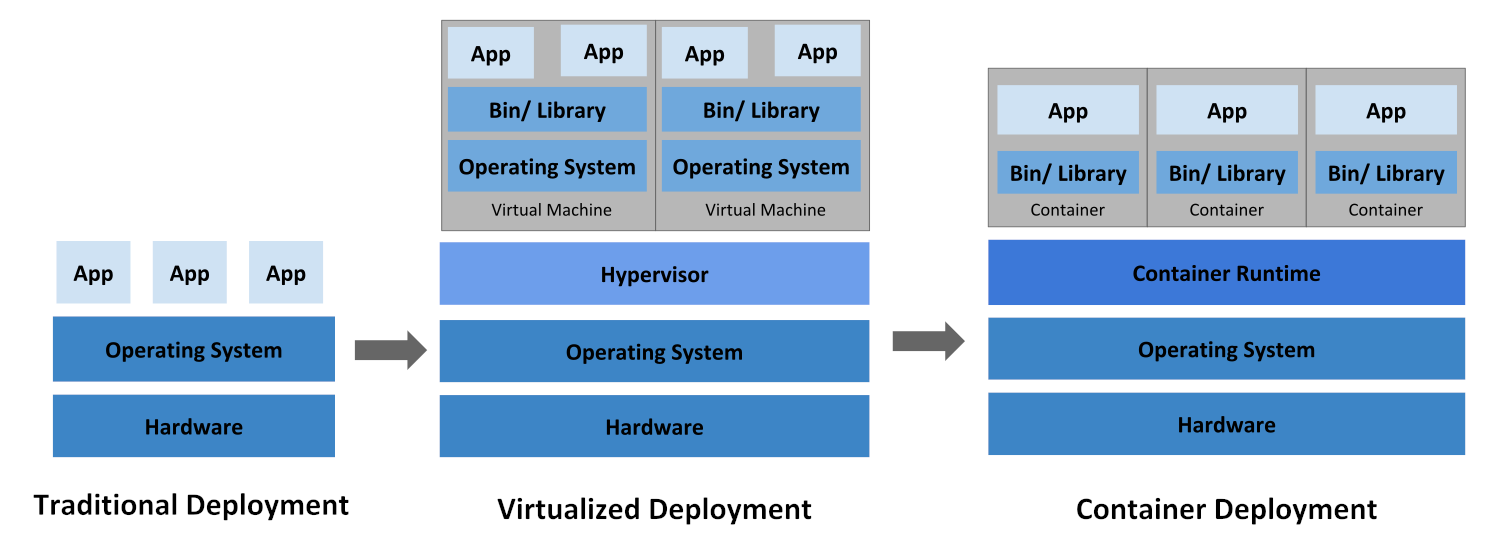
Evolution of containers (source).
But how do you manage these containers at scale, when say you have then spread across multiple physical machines? What happens if one of those machines crashes? How do you distribute the load? This is where something like Kubernetes comes in. Kubernetes is a container orchestration tool, which is a way of automating and managing the state of containers and their resources. You add several machines to a cluster and then tell it what you want to run and it will make sure that remains the case. If a machine suffers a failure or otherwise crashes it will spot that and make sure that what it was running is restarted elsewhere, minimising downtime.
Kubernetes doesn’t manage just containers though and can deal with other resources too. Probably the most convenient of these are ingress resources. These, when combined with an ingress controller, allow you to reverse-proxy traffic from the outside world into services running in the cluster. A core principle of containers is that they can be ephemeral: they don’t keep their data so you can delete them and recreate them as much as you want. In the real world though most applications need some persistent data, so you mount a volume into the containers which do persist. Kubernetes allows you to create and mount these volumes (called “Persistent Volumes”).
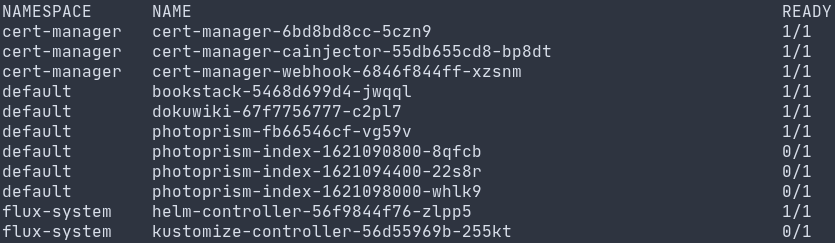
Some running pods in my cluster
So what am I running in my cluster? Currently it runs a handful of my web based applications, since these can scale easily and are easy to set up in a container. I have a separate VM that I use as a dedicated MySQL host for services which require it. My future plans for it involve adding alerting & monitoring to it as well as trying out a Kubernetes tailored backup/restore solution. I’ll briefly discuss some other tools that form the backbone of the cluster itself and help it get up and running:
flux: This is a continuous deployment toolkit based on the GitOps idea. This allows you to specify all of your Kubernetes resources (which are done using YAML files) in a git repository and it will ensure that the cluster matches the state defined in the repository. If you want to add a new service you just add it to the repo and git push and it automagically gets applied. It also has integration with Helm charts: a package manager that joins together a bunch of Kubernetes resources. For instance you could install a nextcloud helm chart and it will create the resources for the service, the volumes, the ingress and so on.
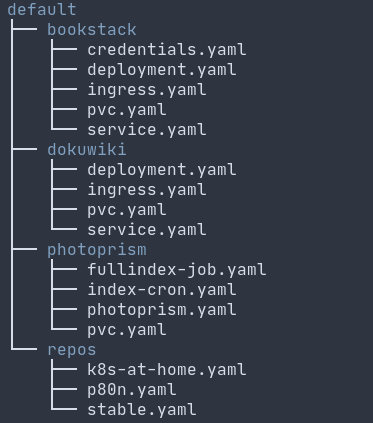
My flux repository
metallb: There needs to be an entry point IP address so that machines outside of the cluster can communicate to the services within. One way of doing this is with a load balancer. Typically this is provided by a cloud provider but when self-hosting you need something like metallb, which announces an IP address to the network that will forward to the service. I use this to expose my ingress controller: the DNS records for my services (e.g. nextcloud.example.com) point to the IP address exposed by metallb, which will forward it to the ingress controller which will then direct it to the right service.
nfs-client-provisioner: Kubernetes supports two ways of creating a volume: static and dynamic provisioning. The former is where you manually create the volume yourself and then create a PersistentVolume manifest that can be claimed by other resources. However this can be cumbersome if you have lots of volumes which is where dynamic provisioning comes in as it detects that a resource requires a volume and will create it automatically for you. Like with load balancing this is usually provided by a cloud provider which will create an elastic volume or object bucket to use, but you can also use a bog standard NFS share that will create a folder for every volume within the mount.
certmanager: This automates the generation of LetsEncrypt SSL certificates that can be used by the ingress to secure HTTP traffic to it. It watches for ingress resources being made and will perform the verification and then give the ingress the issued certificate+key. I have this configured to use CloudFlare’s API to do DNS validation so I don’t even need to expose anything to the Internet.
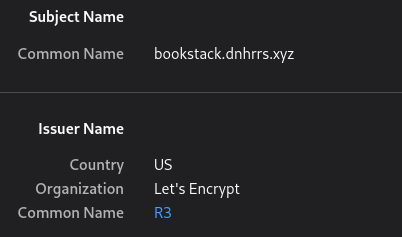
Automatic LetsEncrypt certificates
That pretty much wraps it for now. Now that its up and running the process of deploying a new application should just consist of a couple of commits to a git repo and if it needs to scale I can add more machines to it. Its been an interesting learning experience that is perfect to mess around with at home.